Breaking Down the Barriers: My Journey Into Deep Learning
Feb. 18, 2025As I embark on my journey into the fascinating world of Machine Learning and Deep Learning, I want to share some insights that have fundamentally changed my perspective. The most important revelation? Deep Learning is truly accessible to everyone, and I’m here to debunk some common myths that might be holding you back.
Debunking Common Deep Learning Myths
Before diving deeper, let’s address some misconceptions that often discourage people from getting started with deep learning:
- “You need advanced mathematics” - False! High school math is actually sufficient to get started.
- “You need massive amounts of data” - Not true! Some groundbreaking results have been achieved with fewer than 50 data points.
- “You need expensive hardware” - Wrong again! Many state-of-the-art tools are available for free.
What’s truly exciting about deep learning is its incredible versatility. While neural networks form the backbone of this field, their applications span across numerous domains, transforming industries in ways we never imagined.
The Revolutionary Impact of Deep Learning
The reach of deep learning today is simply staggering. Here are some areas where it’s revolutionizing the field:
🗣 Natural Language Processing (NLP)
- Question-answering systems
- Speech recognition
- Document summarization and classification
- Named entity recognition
- Semantic search
👁 Computer Vision
- Satellite and drone imagery analysis
- Facial recognition
- Image captioning
- Autonomous vehicle systems
- Traffic sign recognition
⚕️ Healthcare and Medicine
- Anomaly detection in medical imaging (CT, MRI, X-rays)
- Pathology slide analysis
- Ultrasound feature measurement
- Diabetic retinopathy diagnosis
🧬 Biology
- Protein folding and classification
- Genomics analysis
- Cell classification
- Protein interaction analysis
🎨 Creative AI
- Image colorization
- Super-resolution
- Noise reduction
- Artistic style transfer
🎮 Gaming & Robotics
- Mastering complex games (Chess, Go, Atari)
- Robot object manipulation
- Real-time strategy gaming
And this is just scratching the surface!
A Journey Through Time: The Evolution of Neural Networks
The story of neural networks is fascinating, and it helps us understand where we are today. Let me take you through this journey:
1943: The Birth of an Idea
Warren McCulloch and Walter Pitts made a groundbreaking discovery: they could model a biological neuron using simple mathematics - addition and thresholding.
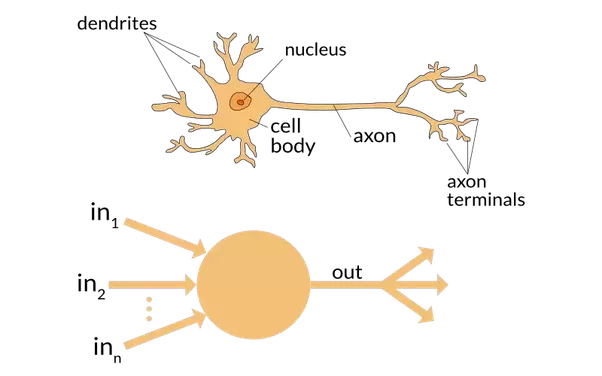
The Rosenblatt Revolution
Frank Rosenblatt took this concept further by introducing learning capabilities to artificial neurons. His vision was ambitious:
“A machine capable of perceiving, recognizing, and identifying its surroundings without any human training or control.”
1986: The PDP Breakthrough
The real breakthrough came with David Rumelhart and James McClellan’s Parallel Distributed Processing (PDP) model. This framework, remarkably similar to modern neural networks, introduced eight key concepts that still form the backbone of today’s deep learning systems:
- Processing units
- Activation states
- Output functions
- Connectivity patterns
- Propagation rules
- Activation rules
- Learning rules
- Environmental interaction
How to learn neural deep learning
Learn by actually implementing deep learning first, see how and where they are used, than learn about tools, and how these tools are made up and than learn about how the tools that make up tools are made.
The hardest part of deep learning is artisanal: how do you know if you’ve got enough data, whether it is in the right format, if your model is training properly, and, if it’s not, what you should do about it?
That is why you need to learn by doing. As with basic data science skills, with deep learning you only get better through practical experience.
Trying to spend too much time on the theory can be counterproductive. The key is to just code and try to solve problems: the theory can come later, when you have context and motivation.
Remember, you don’t need any particular academic background to succeed at deep learning. Many important breakthroughs are made in research and industry by folks without a PhD, such as “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”—one of the most influential papers of the last decade—with over 5,000 citations, which was written by Alec Radford when he was an undergraduate. Even at Tesla, where they’re trying to solve the extremely tough challenge of making a self-driving car, CEO Elon Musk says:
A PhD is definitely not required. All that matters is a deep understanding of AI & ability to implement NNs in a way that is actually useful (latter point is what’s truly hard). Don’t care if you even graduated high school.
This post was made with the help of AI using my notes from the intro of the fast.ai book https://fastai.github.io/fastbook2e/intro.html